首页 > 医疗新闻/ 正文
深度解析医学证据,lxfs.net为你支撑决策
研究提出TRUECAM框架,为病理AI诊断套上“信任锚”
在癌症诊断中,人工智能(AI)模型展现出巨大潜力,但其可靠性常因模型自身局限(如无法有效量化不确定性)以及数据分布偏移(如不同医疗中心、患者群体或染色方法差异)而受到质疑。一个无法提供可信赖风险评估的AI系统,在临床应用中的价值将大打折扣,甚至可能带来误导。如何为这些强大的工具建立坚实的“信任锚”,已成为数字病理学迈向临床实践的核心挑战。
针对这一困境,香港理工大学Zhang Xiaoge、Maximus C. F. Yeung和范德比尔特大学医疗中心Bradley A. Malin合作,提出了一种名为TRUECAM的新型框架。该框架旨在系统性地提升病理AI在数据与模型两个层面的可信度,确保其在真实世界多变环境中的可靠性。研究显示,TRUECAM能显著提升非小细胞肺癌(NSCLC)亚型分类的准确性,并提供有统计学保证的误差率,即使面对陌生数据也能保持稳健。相关内容以“Implementing trust in non-small cell lung cancer diagnosis with a conformalized uncertainty-aware AI framework”为题,发表在《Nature Biomedical Engineering》上。

TRUECAM框架的核心在于三大模块的协同工作。首先,一个名为谱归一化神经高斯过程(SNGP)的模块负责将输入数据映射到一个新的空间,在此空间中数据间的距离得以保留,从而有效识别出与训练数据“格格不入”的输入(如非癌组织),为模型筑起第一道防线。其次,一个“模糊图块消除”(EAT)机制登场,它会自动识别并过滤掉整张切片中那些对分型无益、甚至可能引入“噪音”的非信息性区域。最后,通过“共形预测”(CP)模块,框架能为模型的最终诊断提供一个包含所有可能亚型的“预测集合”,并从统计学上保证该集合包含正确结果的比例达到预设水平,例如95%。
图1直观地展示了这一框架的设计理念与初步成效。其中,图1a概述了TRUECAM如何通过数据可信度(SNGP与EAT)和模型可信度(CP)两个维度来保障AI的整体可靠性。图1b则对比了其应用在专用模型(如Inception-v3)和通用病理学基础模型上的两种工作流程,显示出良好的模型通用性。图1c以一张实际的肺部切片为例,展示了EAT模块如何剔除大量模糊、非信息性的图块,仅保留关键诊断区域,这既提升了效率也聚焦了模型注意力。关键结果如图1e所示,研究团队在TCGA数据集的89名患者测试样本上比较了多种模型加装TRUECAM前后的效果,结果显示,在预设覆盖率为95%和99%时,Inception-v3模型的错误率相对于原始版本分别惊人地降低了72.0%和93.8%。图1f进一步解释了这个现象:通过CP机制,模型在面对不确定病例时选择“弃权”并交由病理医生处理,从而大幅减少了误诊。例如,为达到95%的覆盖率,原始模型在89名患者中错误分类了14位,而加装TRUECAM后,错误数锐减至不足4人。最后,图1g突显了TRUECAM在应对临床“意外”时的价值:当混合了模型训练中从未见过的非癌组织时,原始模型会错误地将它们分为肺癌亚型,而TRUECAM则能有效识别并排除这些域外输入,维持了低错误率。
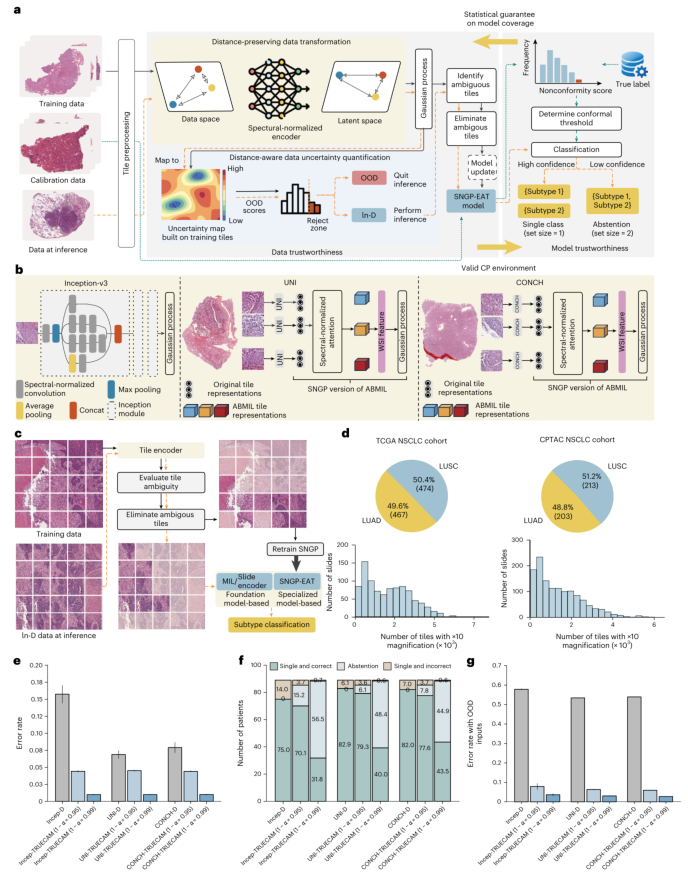
图1 | TRUECAM框架在非小细胞肺癌(NSCLC)亚型分型中的应用概览。 a,TRUECAM框架概览,包含两个核心的信任保障支柱:数据可信度(通过谱归一化神经高斯过程(SNGP)和模糊图块消除(EAT)实现)和模型可信度(通过共形预测(CP)实现)。b,TRUECAM与专用模型(以Inception-v3为例)和通用病理学基础模型(例如UNI、CONCH、Prov-GigaPath和TITAN)集成的两种工作流程。c,EAT机制示意图,展示了其如何识别一张WSI中具有高诊断价值的图块(红色边框),同时排除模糊且可能引入误导的图块(蓝色边框)。d,本研究中使用的数据集的分布和大小概览,包括TCGA、CPTAC和QMH-NSCLC数据集。e,加装TRUECAM后的模型(后缀为TRUECAM)与其原始确定性版本(后缀为D)在患者级别NSCLC亚型分型错误率上的比较,并遵循预设的真实标签覆盖率1-α。f,加装与未加装TRUECAM的模型在患者级别NSCLC亚型分型结果的分类构成比较。g,在涉及1:1混合了域内(In-D)和域外(OOD)输入的真实世界NSCLC分型场景下,TRUECAM实现了显著更低的错误率。e-g中的结果基于TCGA数据集(n=20)。UNI和CONCH与ABMIL配对进行推理。e和g中,数据以均值±95%置信区间表示,基于n=20个独立训练的模型,每个模型进行500次CP评估。
在深入评估各个模块时,SNGP的优势尤为突出。图2展示了其相较于传统确定性模型和MC Dropout不确定性方法的性能提升。在独立的外部数据集(CPTAC)上验证时(图2a-d),无论在图像块级别还是患者级别,SNGP的准确率和AUROC均显著优于其他方法,显示出更强的泛化能力。当与共形预测结合后(图2e-h),SNGP在保证统计覆盖率的同时,其输出的“预测集合”平均尺寸更小,意味着模型在大多数情况下能给出更明确的单亚型诊断。图2i-l进一步剖析了患者层面的分类构成,清晰地表明SNGP不仅带来了更多的“单亚型且正确”的诊断,而且其“决定性回答错误率”在所有比较方法中始终最低,尤其是在更严格的置信度要求下(α=0.01),错误率可降至1.9%以下,实现了极高的诊断精度。
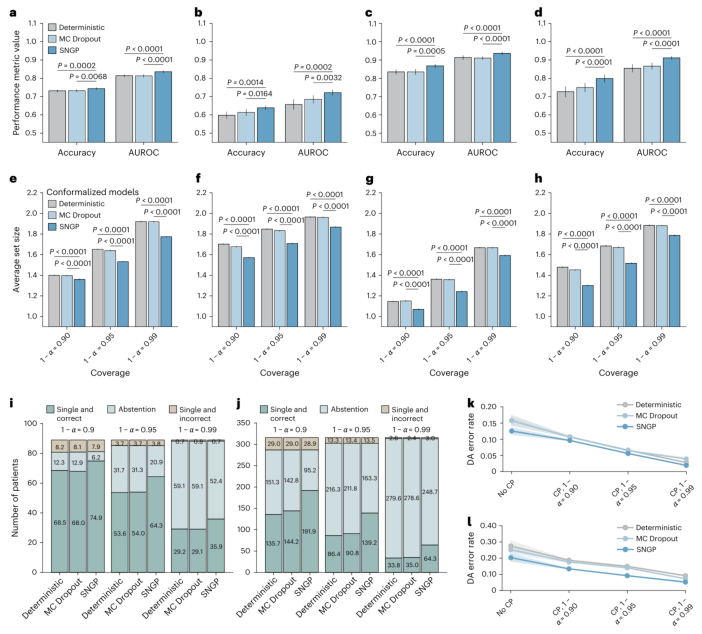
图2 | 基于Inception-v3的NSCLC亚型分型中,距离感知不确定性估计和共形预测(CP)的评估。 a,在TCGA测试集上的图块级别准确率和AUROC。b,在CPTAC外部验证集上的图块级别准确率和AUROC。c,在TCGA测试集上的患者级别准确率和AUROC。d,在CPTAC测试集上的患者级别准确率和AUROC。e,TCGA测试集上图块级别的CP平均预测集大小。f,CPTAC测试集上图块级别的CP平均预测集大小。g,TCGA测试集上患者级别的CP平均预测集大小。h,CPTAC测试集上患者级别的CP平均预测集大小。i,TCGA测试集上患者级别分类构成。j,CPTAC测试集上患者级别分类构成。k,TCGA测试集上患者级别的决定性答案(DA)错误率。l,CPTAC测试集上患者级别的决定性答案(DA)错误率。对于a-d, k-l,数据以均值±95%置信区间表示,基于n=20个独立训练的模型,对于e-h,每个训练模型进行500次CP评估。统计显著性通过单侧Wilcoxon符号秩检验评估。
数据的“纯净度”对模型学习至关重要。图3阐述了EAT模块如何通过“数据瘦身”来“以少胜多”。研究团队对SNGP生成的图像块特征进行聚类分析,发现存在一个高度“模糊”的图块簇(图3a),其中来自两种肺癌亚型的图块混杂在一起,无法提供明确的诊断信号。通过可视化(图3b-c),这些区域与模型和病理医生眼中的低信息量区域高度重合。将其剔除后,模型的性能反而得到提升(图3d)。在患者分类层面,无论是内部数据还是外部数据(图3e-f),应用了EAT的模型都表现出了更优的分类构成,即在牺牲极少“弃权”案例的情况下,换取了更少的“单亚型但错误”诊断,证明了这一策略的有效性。值得注意的是,对于专用模型(Inception-v3),EAT减少了约66%的待处理图块,大幅提升了推理效率。
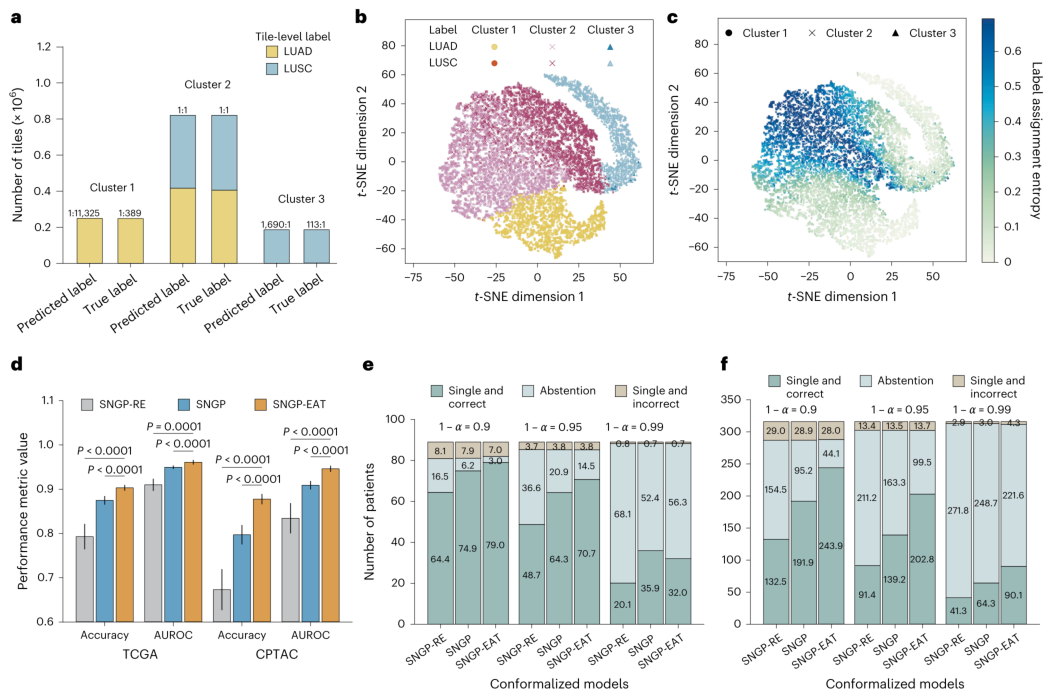
图3 | 在基于Inception-v3的NSCLC亚型分型中,对EAT的评估。 a,使用SNGP生成的图块表示进行k-means聚类后,每个图块簇中被SNGP预测为LUSC与LUAD的图块数量及比例,以及相应的基于切片级别诊断的真实标签。b,基于t-SNE的图块簇和真实标签可视化。c,在t-SNE可视化基础上,以标签分配熵衡量的图块级别模糊度。d,在TCGA和CPTAC测试集上的患者级别分类性能。e,三个基于SNGP的共形化模型在TCGA上的患者级别分类构成。f,在CPTAC上的患者级别分类构成。对于d,数据以均值±95%置信区间表示,基于n=20个独立训练的模型,每个模型进行500次CP评估,统计显著性通过单侧Wilcoxon符号秩检验评估。
一个值得信赖的AI模型还应是“公平”的。图4评估了TRUECAM在不同性别和种族亚组间的表现差异。结果显示,应用了SNGP和EAT的模型在提升整体准确率的同时,也显著缩小了不同亚组间的准确率差距(图4a-d)。而在应用CP后,TRUECAM同样在预测集合大小的公平性上表现卓越(图4e-h),这意味着模型对不同背景的患者都能提供同样可靠的不确定性评估。尤为重要的是,这一公平性提升是EAT模块自动实现的,无需在训练过程中施加任何显式的公平性约束。
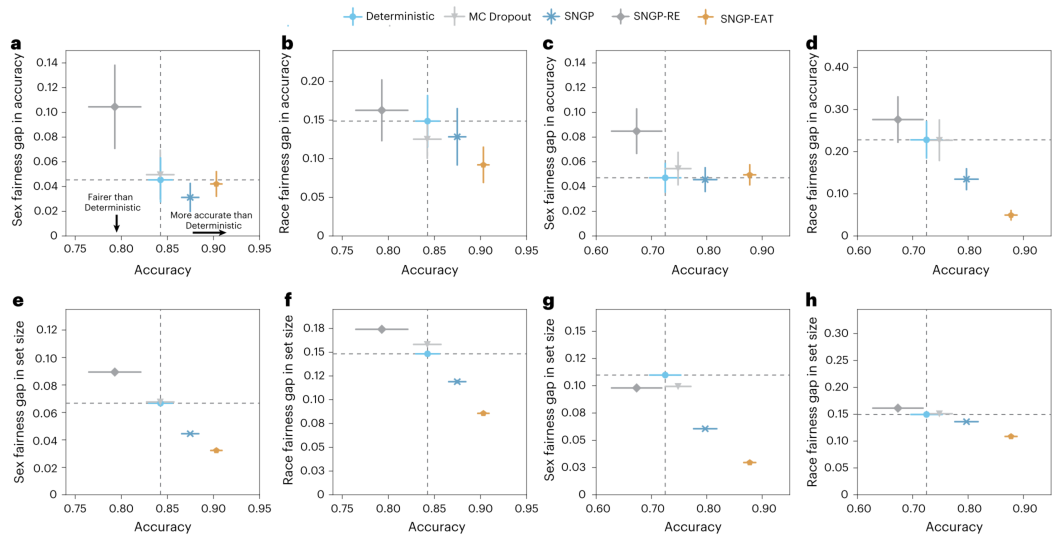
图4 | TRUECAM的公平性评估:基于最佳和最差表现人口统计亚组之间的指标值差异与NSCLC亚型分型总体准确率的关系。 a-d,在未激活CP的情况下,TCGA(a,b; n=189)和CPTAC(c,d; n=416)上区分LUAD和LUSC的性别-wise(a,c)和种族-wise(b,d)准确率差距与总体准确率的关系。数据以均值±95%置信区间表示,基于20个独立训练的模型。 e-h,在α=0.05且激活CP的情况下,TCGA(e,f)和CPTAC(g,h)上性别-wise(e,g)和种族-wise(f,h)预测集大小差距与总体准确率的关系。数据以均值±95%置信区间表示,基于20个独立训练的模型,每个模型进行500次CP评估。
对于AI临床应用的另一大障碍——分布偏移,TRUECAM也给出了解决方案。图5展示了其在识别域外数据(OOD)方面的强大能力。结果表明,基于不确定性的OOD评分能最有效地将正常组织与癌组织区分开(图5a-b)。当将这些检测机制与共形风险控制(CRC)相结合时,即使OOD数据混入的比例不断变化(图5d),模型的整体覆盖率依然能稳定维持在预设水平,这相当于为AI系统增加了一层动态调节的安全阀,确保了其在复杂临床环境中的可靠性。此外,通过“分布偏移控制”(图5e-j),TRUECAM还能指导用户在部署模型前过滤掉不适合其处理的异常数据,从而在新的人群或医疗中心维持高性能。
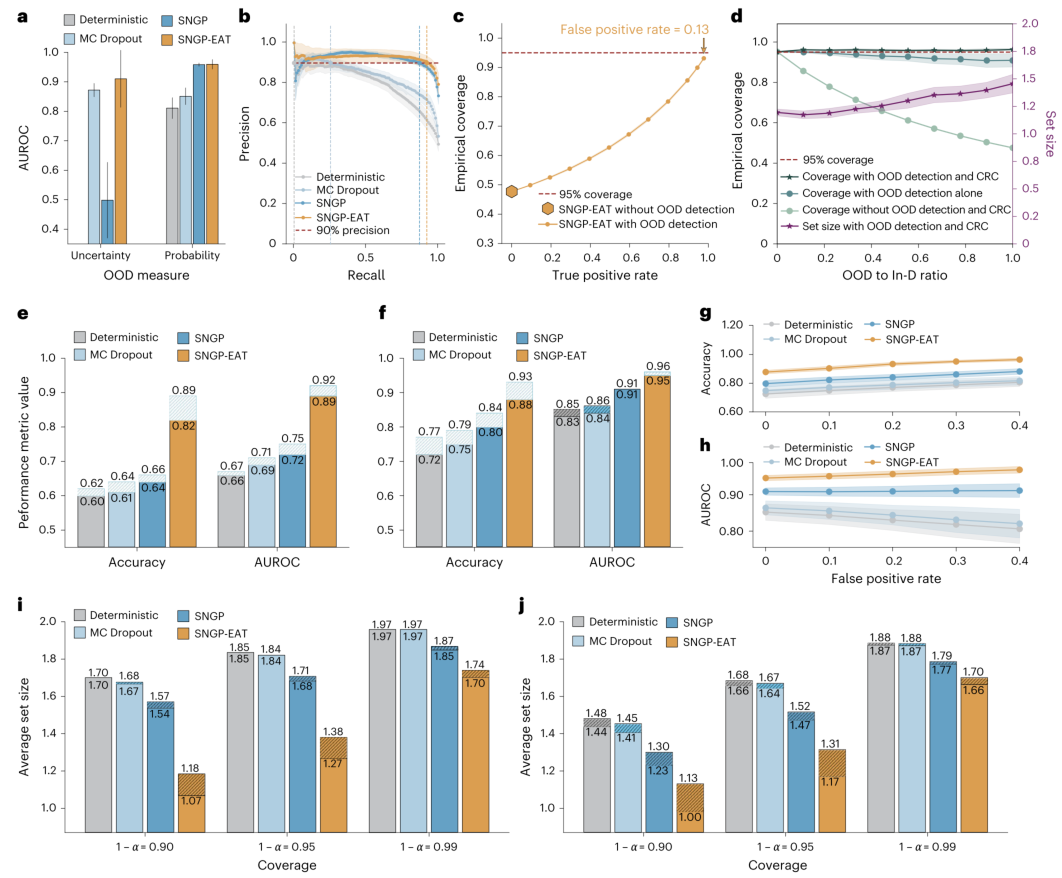
图5 | 基于Inception-v3的NSCLC亚型分型中的OOD检测和分布偏移控制评估。 a,概率型和不确定性型OOD评分在区分In-D和OOD WSI时的AUROC性能。b,不同模型的精确度-召回率曲线。c,作为OOD检测真阳性率(TPR)函数的经验覆盖率。d,作为OOD与In-D比例函数的、在共形风险控制(CRC)下的经验覆盖率。e,应用分布偏移控制(DSC)前后,在CPTAC测试集上的患者级别准确率。f,应用DSC前后的AUROC。g,作为OOD评分阈值(以FPR表示)函数的准确率。h,作为FPR函数的AUROC。i,作为FPR函数的CP平均预测集大小。j,作为FPR函数的DA错误率。对于a-b,数据以均值±95%置信区间表示,基于n=20个独立训练的模型。对于e-h,数据以均值±95%置信区间表示,基于n=20个独立训练的模型,每个模型进行500次CP评估。
TRUECAM的优势并不局限于专用模型。如图6所示,当将其封装到UNI和CONCH等先进的病理学基础模型上时,同样带来了显著的性能飞跃。在准确率(图6a)、CP覆盖率(图6b-c)和患者分类构成(图6d)等多个维度上,加装TRUECAM的版本均优于原始模型。在OOD检测(图6e-f)和CRC整合(图6g-h)方面也观察到了一致的提升效果。更重要的是,在极端图块保留率的测试中(图6k-l),TRUECAM的EAT策略展现出了强大的信息筛选能力,即使仅保留0.1%的图块,也能维持甚至提升分类准确率,而随机保留图块则会导致性能急剧下降。这意味着EAT能精准抓取诊断核心,极大提升推理效率。
TRUECAM的通用性并不仅限于肺癌。研究团队还在另外五个涵盖脑肿瘤、乳腺癌、肾癌等器官的亚型分型任务上进行了验证,其中甚至包括一个包含46种癌症类型的泛癌分类挑战。结果表明,无论是在专用模型还是基础模型上,TRUECAM在绝大多数场景下均提升了分类准确率和F1分数,平均降低了21.6%的平衡错误率,同时平均减少了超过20%的推理计算量。这种跨器官、跨癌种、跨任务复杂度的稳定表现,进一步确立了TRUECAM作为一个通用框架的定位。
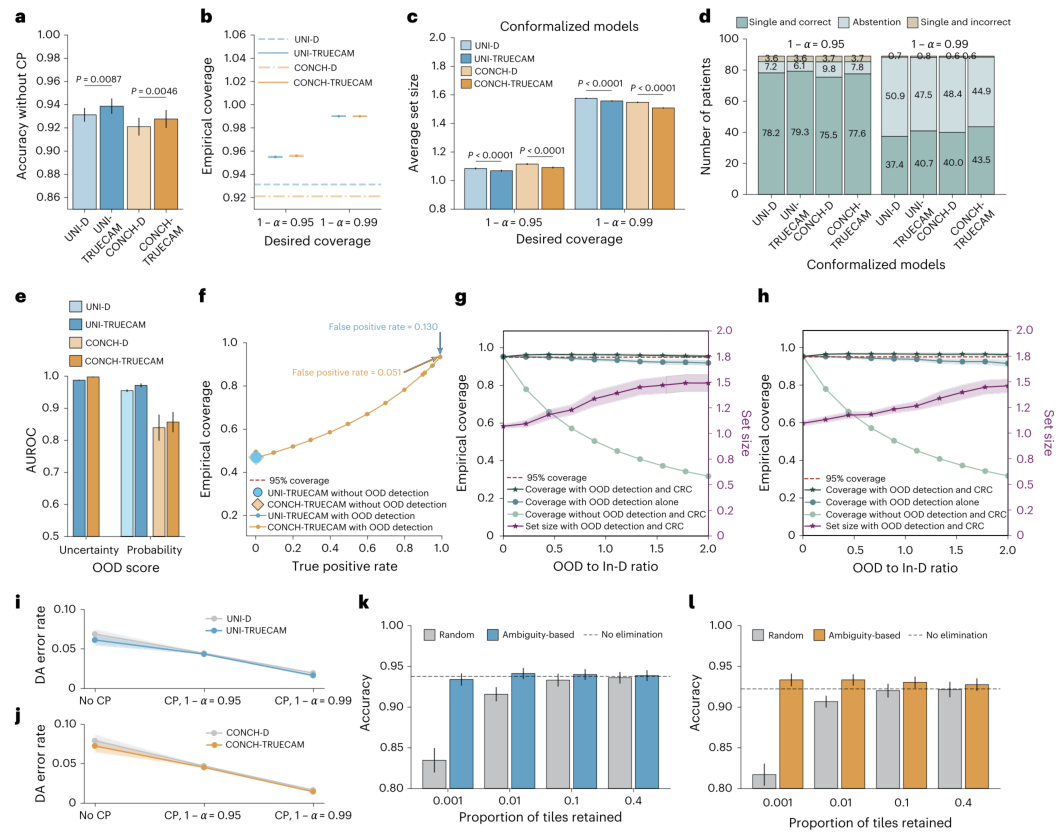
图6 | 使用基础模型UNI和CONCH对TRUECAM进行评估。 报告了TCGA(n=189)上的结果。a,基于基础模型的ABMIL在有无TRUECAM(后缀“-TRUECAM”和“-D”)的情况下的分类准确率(未使用CP,n=20次独立运行)。b,有和无TRUECAM的经验覆盖率比较(n=20)。c,有和无TRUECAM的CP平均集大小比较(n=20)。d,有和无TRUECAM的患者分类构成比较。e,两种不同的OOD评分在识别模型范围外切片方面的性能。不确定性评分不适用于UNI和CONCH的原始版本(n=20)。f,经验覆盖率作为OOD检测TPR的函数(α=0.05)。g,h,在CRC下,UNI-TRUECAM(g)和CONCH-TRUECAM(h)的经验覆盖率和集大小,作为OOD与In-D比例的函数。i,j,在不同CP设置下,UNI(i)和CONCH(j)有和无TRUECAM的患者级别DA错误率比较。k,l,使用TRUECAM基于模糊度的图块消除策略与随机图块消除策略的UNI-TRUECAM(k)和CONCH-TRUECAM(l)分类准确率比较,作为每张切片保留图块比例的函数(n=20)。对于a-c, e, k-l,数据以均值±95%置信区间表示,跨n=20个独立训练的模型,统计显著性通过单侧Wilcoxon符号秩检验评估。对于g和l,误差带以均值±95%置信区间表示,跨n=20个独立训练的模型。
在可解释性方面,通过对比病理医生的标注与模型生成的可视化结果,清晰地展示了TRUECAM的优势。TRUECAM识别出的“低模糊度”区域恰好是医生认为最具诊断价值的地方,而高模糊度区域则对应着背景、炎症或坏死等非特异性区域。经EAT过滤后,模型最终的注意力图也准确地聚焦于体现腺癌或鳞癌特征的细胞形态区域。研究团队还引入了“注意力效率”这一量化指标,衡量模型高注意力区域与病理医生标注的诊断相关区域的重合度,结果显示TRUECAM在所有模型类型上均显著优于传统注意力机制。则量化了效率优势:SNGP的推理速度是MC Dropout的五倍,同时EAT机制通过大幅减少待处理图块,显著加快了整体分析流程。
总而言之,TRUECAM框架通过将不确定性量化、数据筛选和统计保证有机结合,为病理AI的临床转化提供了一条坚实路径。它不仅提升了诊断准确性,更重要的是建立了一个可审计、可协作的人机合作模式,让AI在最自信时提供决策支持,在不确定时主动寻求人类专家帮助。值得强调的是,这一协作机制具有渐进式的自我完善能力:被标记为异常或弃权的病例可由病理医生标注后重新纳入训练,使模型的可信作用范围得以在受控且透明的方式下持续扩展。未来,该框架有望在更多交互式、多层次的病理诊断任务中得到验证和拓展,推动AI从“辅助工具”向“可信赖伙伴”的角色演变。
小提示:本篇资讯仅在梅斯医学APP中开放阅读,请扫描二维码直接下载APP
